Projects

Context-Aware Zero-Shot Anomaly Detection in Surveillance Using Contrastive and Predictive Spatiotemporal Modeling
Supervisors: Prof. Dr. Md. Ashraful Alam, Md Tanzim Reza
Developed a novel zero-shot anomaly detection framework that identifies abnormal events in surveillance footage without requiring any anomaly examples during training. The system combines spatiotemporal transformers with vision-language understanding to detect previously unseen threats in real-time.
Key Innovation: Introduced a dual-stream architecture integrating TimeSformer for spatiotemporal feature extraction, DPC-RNN for predictive temporal modeling, and CLIP for semantic context alignment—enabling true zero-shot detection with context awareness.
Technical Approach: Jointly trained the model using InfoNCE and Contrastive Predictive Coding (CPC) losses to learn normal behavior patterns. A context-gating mechanism modulates predictions based on scene-specific cues, reducing false alarms by adapting to different surveillance environments.
Results: Achieved 84.5% ROC-AUC and 72.3% PR-AUC on the UCF-Crime dataset, outperforming state-of-the-art zero-shot methods including AnomalyCLIP (82.4%) while maintaining competitive detection latency of 0.45 seconds.
Tech Stack: Python, PyTorch, Hugging Face Transformers, TimeSformer, CLIP, DPC-RNN, OpenCV, UCF-Crime dataset
Blue-Light Blocking Glasses Using Machine Learning
Instructors: Annajiat Alim Rasel, Sadiul Arefin Rafi
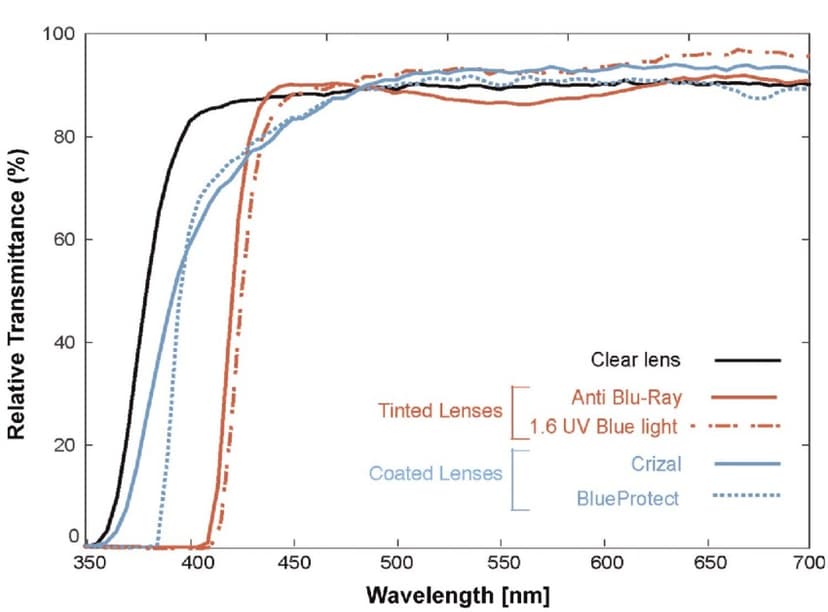
Developed machine learning models to predict and analyze the spectrophotometric properties of commercial blue-light blocking lenses, evaluating their effectiveness in filtering circadian-proficient wavelengths (455-560nm) while preserving visual clarity across diverse lighting conditions.
Research Methodology: Tested 50 commercial blue-blocking lenses under 5 distinct light sources (sunlight, fluorescent, incandescent, LED, and tablet displays), measuring absolute irradiance across the visible spectrum (380-780nm).
Model Performance: Implemented KNN, SVM, and Linear Regression. The KNN model achieved superior performance with 91.4% R² score, 5.921 RMSE, and 3.844 MAE, significantly outperforming SVM (48.3% R²) and Linear Regression (79.7% R²).
Key Findings: Red-tinted lenses transmitted the least circadian-efficient light, while orange-tinted glasses demonstrated the highest transmission specificity for blocking physiologically active light in daylight conditions.
Tech Stack: Python, Scikit-learn, Pandas, NumPy, Matplotlib, OpenRefine, SVM, KNN, Linear Regression, Spectrophotometric Data Analysis
Comparative Evaluation of Clustering Algorithms on the Wine Dataset with Stability Analysis
Instructor: Moin Mostakim
Developed a novel Stochastic Clustering Neural Network (SCNN) inspired by Variational Autoencoders to perform uncertainty-aware clustering on the Wine dataset, incorporating probabilistic latent representations to quantify cluster assignment confidence.
Novel Architecture: Designed a VAE-inspired stochastic neural network featuring an encoder-decoder structure with reparameterization trick, enabling gradient-based optimization through stochastic sampling while learning meaningful latent representations.
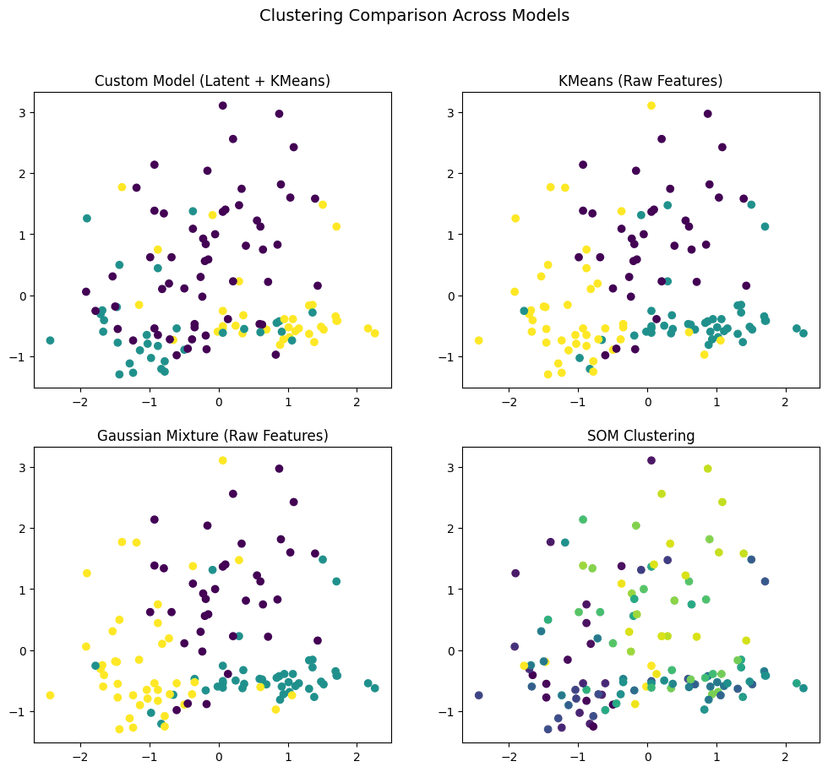
Comparative Analysis: Conducted comprehensive evaluation against classical baselines (K-Means, GMM, SOM) using Silhouette Score, Adjusted Rand Index (ARI), and Normalized Mutual Information (NMI). Introduced stability analysis across multiple random seeds.
Key Findings: While GMM achieved highest accuracy (78.44% ARI), the SCNN provided unique uncertainty quantification capabilities with 0.4885 stability variance. SOM demonstrated extreme instability (974.89), highlighting sensitivity to initialization.
Tech Stack: Python, PyTorch, Scikit-learn, NumPy, Pandas, Matplotlib, Seaborn, Wine Dataset
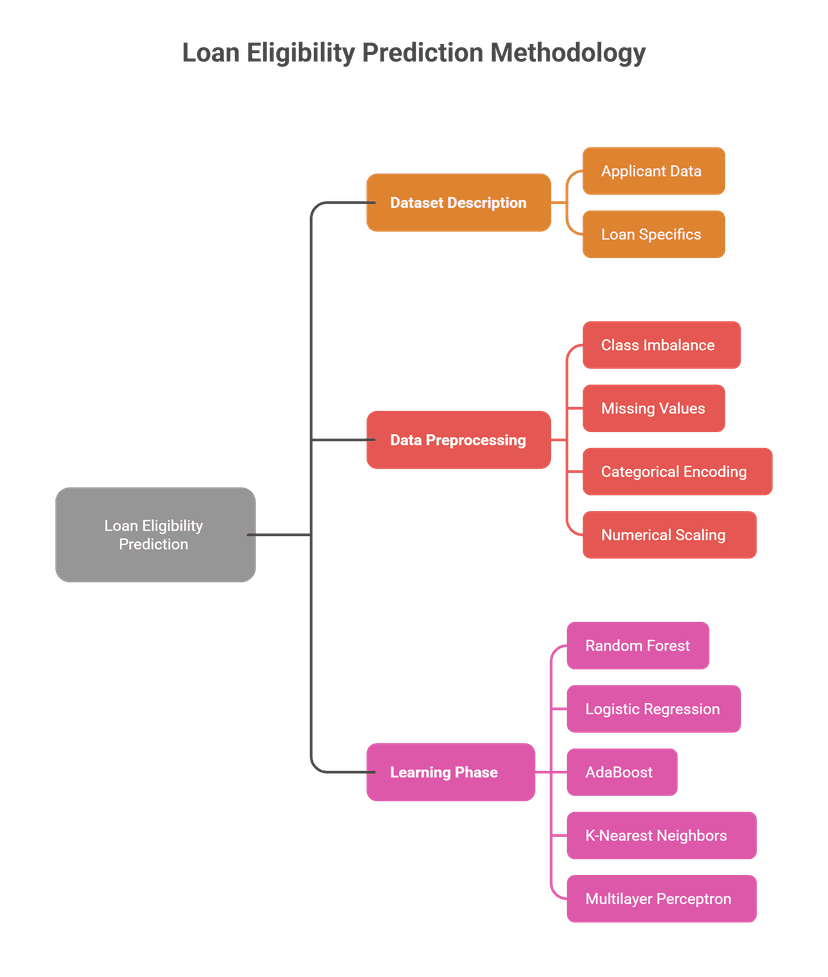
Loan Eligibility Prediction Using Machine Learning Models with SMOTE for Class Imbalance
Instructor: Prof. Dr. Chowdhury Mofizur Rahman
Built an automated loan eligibility prediction system for Dream Housing Finance Company using machine learning classifiers to streamline the approval process based on applicant demographics, financial data, and credit history.
Data Preprocessing: Implemented comprehensive preprocessing including median/mode imputation for missing values, one-hot encoding, feature scaling, and SMOTE to address severe class imbalance in loan approval data.
Model Comparison: Evaluated five ML algorithms—Random Forest, Logistic Regression, AdaBoost, KNN, and MLP—using accuracy, precision, recall, and F1-score metrics. Random Forest and MLP achieved highest accuracy (89.29%), with MLP demonstrating exceptional recall (96%).
Key Insights: Correlation analysis revealed ApplicantIncome (0.57 with LoanAmount), CreditHistory, and LoanAmount as strongest predictors. However, all models struggled with False class prediction, indicating need for advanced imbalance handling.
Tech Stack: Python, Scikit-learn, Pandas, NumPy, Matplotlib, Seaborn, Imbalanced-learn (SMOTE), ensemble methods